// breathing LED, for @frankippolito // simplest possible sketch, using only loops and IO, no PWM hardware or libraries. // copy and paste this into a new Arduino sketch, modify the indicated parameters and upload. // (v2 some corrections and comment mods) #define LED_PIN A0 // which pin is the LED on // CHANGE THIS ^^ FOR DIFFERENT PIN #define LED_GAMMA 4.4 // gamma correct the brightness curve // CHANGE THIS ^^^ FOR DIFFERENT BREATH CURVE // larger values make it "pop" more at the end #define LED_OFF_STATE LOW // in theory the arduino can sink more current than it can source, #define LED_ON_STATE HIGH // so swap these if you're wiring the other side of the LED to VCC rather than GND #define PWM_MIN 0 // LED brightness minimum (0..255) #define PWM_MAX 255 // LED brightness maximum (0..255) // there is no need to use a series resistor for the LED as long as you manage the maximum on time. PWM is More efficient #define DELTA_RATE 0.001 // LED brightness change per delta step (rate of change) // CHANGE THIS ^^^ TO TUNE RATE #define DELTA_LOOPS 2 // how long to spend in the PWM loop per delta step (major divider)
// the rate of the "breathing" is going to be a slightly complication multiplication of // the processor clock speed, some overheads, and the DELTA_RATE divided by DELTA_LOOPS // // Code is written so the MIN and MAX values can be tweaked later without altering timings. // There is also potential for "gamma correction" if the log brightness curve isn't sophisticated // enough // // update: Changing the DELTA_RATE is now the best way to fine-tune the breathing rate. // It scales better and with finer control than the LOOPS, since it's a floating point number.
void setup() { Serial.begin(57600); // needed on some boards pinMode(LED_PIN, OUTPUT); digitalWrite(LED_PIN, LED_OFF_STATE); } int direction_up = true; float linear = 0.0; void loop() { // update our linear value if(direction_up) { // going up if( (linear += DELTA_RATE) >= 1.0 ) { // we hit max linear = 1.0; direction_up = false; } } else { // going down if( (linear -= DELTA_RATE) <= 0.0 ) { // we hit max linear = 0.0; direction_up = true; } } // turn the linear value into an absolute PWM brightness via the gamma curve float gamma = pow(linear, LED_GAMMA); gamma = gamma * (float)(PWM_MAX - PWM_MIN) + (float)PWM_MIN; int pwm = gamma; //Serial.println(pwm); // if we have PWM hardware available, this next bit would be just a call to set it's value and a wait(), // but we're not going to assume any is available on the pin you want, so we just use raw loops to do // rough-and-ready PWM to the LED for a few turns. for(int j = DELTA_LOOPS; j>0; j--) { int i; // spend some time on for(i = pwm; i>0; i--) { digitalWrite(LED_PIN, LED_ON_STATE); } // spend some time off for(i = (256-pwm); i>0; i--) { digitalWrite(LED_PIN, LED_OFF_STATE); } } }
Here's the latest thing I've built: (screen not entirely tucked in yet...)
I'm into wearable technology, now.
Base specs for the machine are:
Raspberry Pi Zero - 1Ghz ARM processor, 512Mb of RAM
8Gb SD card with Raspbian Jessie
WiFi 802.11n adapter
MPU6040 accellerometer/gryo inertial sensor
1/5" PAL/NTSC LCD television, 240x180 pixels
Turnigy Nanotech 950mAh 1-cell LiPo
Polulu 5v step-up voltage converter/regulator.
2 old mouse buttons
The MPU6040 sensor is used by my 'gyromouse' driver, which means the manipulator has a fully functional X11 GUI interface. I can run most linux apps, (that don't require large screens or shift-click combos) and even use the 'Florence' on-screen keyboard if I need to tap out a few characters. (yes, it's painfully slow.)
The screen is just resting on top. Once I push it in, I'm not sure it's coming back out.
What makes the device actually useful is that it's a full Linux machine, with a WiFi connection. That makes any nearby PC that can run SSH or VNC into a handy keyboard, mouse and 'big' screen. Or even a remote PC - once the manipulator is on the network, it doesn't matter where it is, or you are. It acts very much like a 'cloud server' which just happens to be located on your wrist.
What I _can_ easily do is pre-create the equivalent of desktop shortcuts that run shell scripts or any arbitrary action you can do on a linux machine. The ultimate programmable remote control - that can also show you progress and logfiles.
Why do I need such a thing? Well, personally, I've found that doing digital astronomy is a pain in the ass if you have to keep running between the telescope and PC. Especially if one is inside the house. Or you're in the field, literally.
The main person who will get to use it is a unix security expert, for whom having a wifi-scanning wrist strap (running Kismet) is a useful work tool.
Neither application requires a lot of user interaction - just enough to navigate a few menus and click a 'start' button or two - but they're apps which have a lot of status displays it's handy to keep an eye on.
The build proceeded in very careful steps. I'd actually developed the software in advance on my Pi A+, so when the Zero and other hardware pieces arrived, I was basically ready to go. It only took a couple of hours to hook up the primary components and give everything a whirl.
The parts on arrival.
It's always good to check your parts individually if you can, so I test-fired up the Pi with my prepared OS on a standard monitor/keyboard setup, despite the ridiculous relative size of the connectors and cables. All fine.
HDMI cable with an end-cap made of computer
After that, I spent a good hour or two just staring at all the pieces, physically and mentally stacking them in various ways, and trying to plan how they were all going to fit together.
Jenga!
The RCA connector for the LCD module's video input was far too big, and even the 4-pin "low profile" socket is comparatively large.
80-year old socket technology.
So the first thing was to pop off that connector and direct-solder to the Pi's video output. I also de-cased the WiFi adaptor and direct soldered that to the Zero as well.
Naked WiFi dongle.
Almost like they expected us to do this kind of thing.
Then time for another test, to make sure the LCD module was working.
First LCD test
Perfect. By this time it was getting late and so I wound down by wiring up the Polulu voltage converter to a handy LiPo and testing that out. I hadn't used a Polulu before, but I'm impressed. Quality little component. Get some.
Not actually sure of the capacity of this battery. About 600mAh?
I didn't want to plug an untested power converter it into my shiny new machine, so I tried it first on an old Arduino board that's seen it's share of action.
Your bravery is appreciated.
And to finish the night, the first un-tethered boot of the machine:
First boot from battery. All systems go. Power stable for 63 minutes.
A good first day. I slept well.
The next day, I added the MPU6040 inertial sensor and a single membrane button I pulled from an old remote control. I put some heatshrink tubing around various easy-to-short components like the WiFi adapter, and then very carefully folded up all the boards into a neat little package.
Now it's looking more like a... um... thing.
Another boot to make sure it's all still working, and if gyromouse has started up properly. Which it had. It took longer to find an on-screen keyboard that worked properly. "matchbox-keyboard" is the one you'll see mentioned, but it was chewing up my CPU because of a known bug, and I switched to "Florence" instead. Which has different issues, but nevermind.
Taking "hunt and peck" to a new level, but the GUI is useable.
Now that I had a mouse-equivalent and an on-screen keyboard, I could finally run a few apps. Like the web browser.
Doing a google search
Or kismet:
Detecting nearby Wifi devices...
Or even Minecraft.
At this point I was feeling pretty satisfied with myself. I spent the next day or two tuning gyromouse, setting up the desktop and generally getting everything nice.
It's this point where I started to realize just how much power the LCD module was consuming. Not actually the screen, so much as the video decoder chip that drives it. The module specs say "120mA at 5V" and really means it. I suspect most of that goes through the decoder, which in normal operation gets almost too hot to touch.
The LCD power consumption will be important later, because addressing it has become the one remaining issue in the build, though not for the reason you probably think.
Apart from that, everything was going well. Really well. (too well?) All the computer hardware and software was working, and all I needed to do now was fit it into some kind of case. I had just the thing in mind, and was checking the mailbox every day in anticipation.
Then it arrived! My Official Doctor Who Vortex Manipulator! Batteries Included! I've just got to scoop out the old insides, and put my hardware in its place.
'cause if you're gonna build a computer into a wrist-strap, why not do it with some style?
Yes, I'm a fan, but I also appreciate the thought that went into this particular prop: Capn' Jacks' personal device. Half wallet, phone, keys, and watch. So sensible an idea that no-one gives it a second thought. Well of course future advanced humans strap their mobiles to their wrists on cool beat-up leather bands. Why wouldn't you?
Why don't we?
But then it became obvious - it wasn't going to fit. At least, not the toy version. The real prop is about 50% bigger and probably would have worked nicely. But an accurate replica is also about twenty times more expensive, and I'd never have been able to bring myself to damage it.
The original toy also has one working button, which activates a blue light! Wow!
At this point, I had a long, long think. And a talk to my friends about leather-work. Basically, I had two choices: try to fit the manipulator into the toy, or get a new custom wrist-strap specially for the project.
I chose both.
Eventually I'll get a custom wrist-strap built - already made inquiries. I'll have to build a hard case to hold the components too. (Or use an Altoids gum tin, perhaps, since that seems the right size.) But in order to figure out the issues, I decided to go ahead and try to stuff everything into the toy anyway. I didn't have any real use for it otherwise, and I figured I'd learn a few things that would be useful in building the "real" manipulator.
And I expected to fail. The Pi Zero is slightly bigger than the strap is wide. I didn't expect it to fit. It shouldn't have fit. But somehow it did.
Bigger on the inside?
Next time, I'll show you how I managed it. Also, how I snapped the SD card containing the entire OS in the process, I'll sum up where I've got to, and the few problems left, and what's next, It's a rollercoaster.
So I had a weird call today from one of my electronics parts suppliers, and apparently they "can't ship LiPos anymore", so that part of my order has been refunded.
Given this particular LiPo is about the size of a credit card and I've ordered enormous batteries from HobbyKing in the past - this sounded strange to me! So I looked into it and yes, the internet boards are newly filled with hate for Australia Post and IATA over the reclassification of LiPos as "class 9" dangerous goods.
Or something. No-one's really sure, except AusPo won't take their batteries anymore.
What I think that means is that a whole new documentation path needs to be applied for transporting LiPos via air, and most of Australian Posts' inter-city mail goes that way. And AusPo either doesn't have the ability, or doesn't want to, supply all the new paperwork.
Sounds annoying, until you realize that it's not just big RC batteries, it's apparently anything with lithium. Installed or not. Coin cells included. Which means people are being told they can no longer send ordinary things like watches and mobile phones through the post that, perhaps they already sold to someone on eBay. It's not even just a matter of "you have to remove the battery before posting" and expecting the receiver to somehow find a matching replacement - look at a modern iPhone or iPad. Remove the battery - how?!?!
Couriers are apparently still able to get LiPos through, at increased cost of course. But there's vast amounts of mail in international transit that might end up being returned because it doesn't have the required documentation. Maybe.
So, the nations primary package carrier now no longer will carry the majority of the things that we use and sell to each other, due to an air transportation safety rule change. Apparently they hate electronic mail so much they're withholding our electrons.
Makers are particularly hard hit, because we can't get parts, and we can't ship our creations. Well, not using our "national infrastructure" - in which case, what's it for?
The rule change may even affect carry-on luggage for plane passengers. Or it might not. It might all just be temporary, while they sort out systems. Or it might be a federal crime to post an iPhone from now on. No-one is completely sure right now, because inconsistencies abound, straight answers are hard to come by, and official documents keep going up and down on the web like well-formatted yoyos..
Hmm. "Well formatted yoyos." I think that's my new name for Australia Post.
So, I'm putting together another "Device". I make them occasionally. Some of them even work.
GyroMouse Prototype. MPU6040 IMU Attached to Raspberry Pi Model A+
While I'm waiting for most of the specific hardware pieces to turn up from all over the internet, I've been slapping together prototype parts and getting the software at least vaguely right. I find that helps.
One goal for this new device is to be compact, so I'm going to use a Raspberry Pi Zero (which I believe is in the post. They're a little hard to get.) So compact that the entire machine can be wrist-mounted, smart-watch style.
And in fact, that's working out fairly well. The Pi Zero is only 70x30mm, 1.5" screens are about 30mm vertical. I have a very specific 80x40x20mm lozenge-shaped space that I need to fit, for reasons which will become obvious in later posts.
You can fit a whole 512mb / 1Ghz processor with GPU hardware in that space, with enough battery to run for hours. WiFi dongles are mostly just connector now.
What's hard to fit is any kind of human-friendly input device. The screen is so small that "touchscreen" tech would be ludicrous. It might be nice to turn the entire surfacebeyond the screen into a capacitive touchpad, but there's no ready sources for such a module, and I'm trying to use Adafruit-level commodity pieces.
Assuming I've got a small linux machine with X11 on my wrist, what's the best way of using that device? Well, mouse is probably still it, in terns of compatibility with existing software. With a mouse you can run an on-screen-keyboard if you have to. It will do everything, if badly.
So to fit something like a mouse in the space available, I've written a little program which listens to a MPU6040 Intertial Management Unit and interprets it's movements as mouse commands. Gyro rotations in X and Y move the mouse cursor, and "taps" on the device (detected by the accellerometer) are interpreted as mouse clicks. At least for today.
To control a tiny computer you need a tiny input device!
As of an hour ago, it works. I had to go through four "i2c" libraries to find one that's stable under node.js, ('i2c-bus" is the one you want.) I'm not happy with the CPU usage to be honest, but it does actually work. I can push the mouse cursor around the desktop by tilting the sensor various ways, and even click on things with considerable difficulty.
Size comparison against my usual mouse.
I'm using Gyros for movement and Acceleration for mouse 'clicks', which is quite different from the "accellerometer" mice I've seen before. The difference there is, accelerators measure "tilt" due to gravity. So in those cases, the mouse cursor acts a lot like the little steel ball in those closed maze puzzle games, rolling around on a flat surface.
Sounds like a good idea at first, but you're asking people to keep the device perfectly flat in order to keep the mouse still. Most people don't intuitively know where "perfectly flat" is.
Gyros sense relative rotational motion. The turning to and fro of an object. Gyros are the most important part of a Quadcopter's IMU, which I know well.
Funny thing, I did a search and I don't think anyone else has built a gyromouse. They all go for accellerometer-mice. Well; technically the Wii-mote, but it also uses the IR lights, so it's a hybrid.
Is this the world's only Gyromouse? To be honest, I haven't really looked that hard.
GyroMouse works off the relative turning motion of the chip to simulate the movement of a mouse. And it detects the "freefall" moment of when you tap the device downwards as a mouse click. It feels horrible, needs extensive tuning, but it functions. I can click on menus. I might be able to extend it to detects 'taps' in various axes, so whacking this particular device from the sides might end up working as other buttons, or maybe the scroll wheel.
I think that's called a "kinetic interface". Similar, although slightly different to "percussive maintenance". But that's kind of the point here... to experiment with what happens when you make a computer aware of it's physical state, and smart enough to respond and adapt.
If you want to be mean, you can denigrate the whole thing as an over-complicated Wii-Mote. And you'd be right. It's a Wii-Mote that doesn't need the Wii. It does everything all by itself.
Right now this is still at proof of concept stage, though later on I'll release the code when it's not quite as embarrassing, and the real hardware has arrived. Leave a comment if you're interested.
Another video; made while testing out the physics engine scripting. This is my most complicated physics demo to date: a fairly complete mechanical model of the Curiosity Mars Rover:
Unlike the 'Atomic Caffeine' demo where you don't really notice that the behavior is a little un-physical, the rover is technically a real vehicle. And you can feel it go over every bump and step. There are moments I forget it's a simulation, and I built it.
Actually, this is what the rover would drive like if it lost independent steering on all four corner wheels (they're not supposed to just spin freely like a broken shopping-trolley wheel like that, they're supposed to be precisely controlled) and was being driven purely on differential speeds, like a treadless tank. You can see why NASA likes this configuration, it's very robust.
The 'hexcode' visual script editor has also come a long way in a short time. This was the initial build script, with a set of COLLADA model files containing the parts like wheels, chassis, camera mast, etc. arranged into 'reference frames' to check that everything was where it should be.
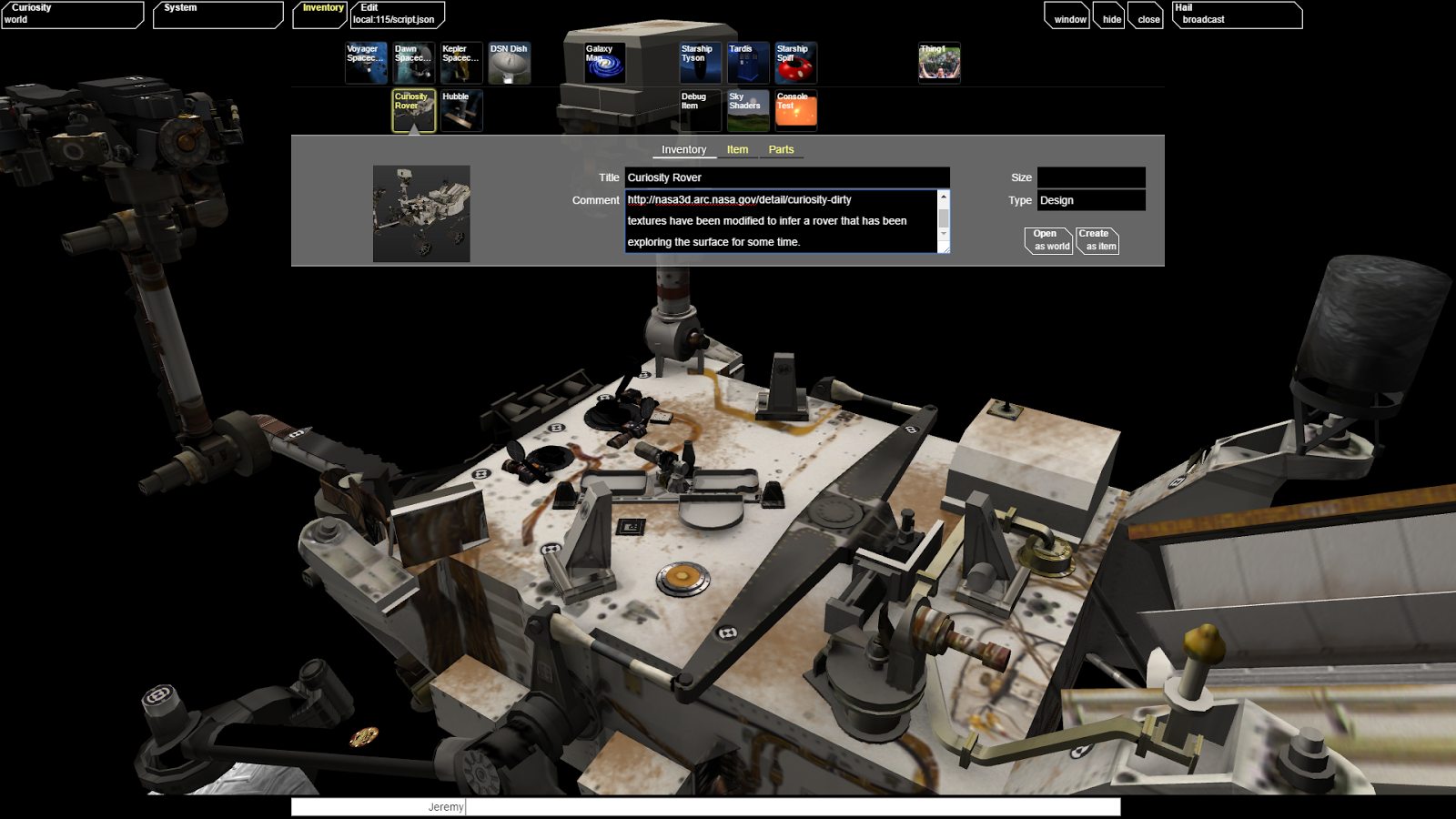
The new item/inventory system is working out well. Most of these designs are edited directly inside the browser from local storage. (No more google docs!) When I'm happy, a copy is uploaded to the web server for everyone to see.
Looks nice with an appropriate 'SkyShader' background, although Simulated Mars really hits the FPS, let me tell you.
The fully completed 'program' for the rover removes the heirarchy, (all frames are attached to the root) and then physical constraints are created between them.
Is it a bird? Is it a plane? No, it's a visual programming language!
Quite a lot of progress. Only a day before, the first attempts to import the rover looked like this:
Explody
Other NASA models are also making an appearance in Astromech. The corner of the Deep Space Network 70m dish can be seen above, and here's the Z2 spacesuit standing on the bridge of my (fake) Starship Tyson over Simulated Mars.
Hi!
That's actually the first "Avatar" in Astromech. The first humanoid figure in the system. And likely to become the default choice for user representation. Although in deference to the sensibilities of a friend of mine, I'm probably going to make a version in a gold lamé material.
Mentally queue track "Journey of the Sorcerer" now.
Historically, I've been a fan of AMD. They make good, cheap processors. Their motherboard chipsets are pretty solid. In 2006, AMD bought out ATI technologies, and started selling graphics cards.
When I built my latest system, I dropped a nice efficient Radeon R7 in there. I've had persistent problems with the machine, even after changing the motherboard, PSU, hard drives, OS, and cooling. The machine stability seems to wax and wane with the release of the AMD Catalyst drivers.
I thought it was just me, but a friend recently put together a machine with the latest and greatest in AMD/Radeon R9 tech to drive a pair of 4K monitors, and her problems are even worse. There was a time it was stable, but drivers changed, and now the machine won't stay up for more than 20 minutes. Trying to run Elite Dangerous is an instant hard crash now. Maximizing the browser window will crash the machine 50% of the time.
And it's not just us. The anger-boards are filled with similar stories. There are rumors several Games companies threatened to write their own Radeon driver set, because their customers were having so much trouble.
The core problem has been ATI's historic secrecy, born from a time when graphics cards could be nice and proprietary, so long as you'd done the driver deal with Microsoft. Patent litigation abounded, as everyone tried to produce a 'better' anti-aliasing or MIP-mapping algorithm and sued everyone else for pushing pixels in near-identical ways. It was toxic.
Since then, graphics cards have become commodity items. No-one cares, or even wants, non-standard bells and whistles. What we really, really need is direct access to the inside guts of the graphics card so we can use it for 'GPU compute' operations, to blat textured polygons onto the screen as fast as possible, and to write "shader programs" in a generic way that works on all computers.
No-one wants "Tesselation" or "PhysX" because those are over-specific features that only do one thing, aren't standard, and can be replicated (often better) with general compute.
NVIDIA has been a leader here with their 'CUDA' architecture. For years, they've allowed people to get up all inside their GPU and know exactly how all the blocks fit together, with no surprises. They figured out that in order for people to get best use out of your product, they have to know how it works.
AMD Graphics also seems to use the necessity to install their OS drivers as a way to get "shovelware" onto the users machine. That's a dangerous trend, because it means they're now also in the business of selling their customers. Not just selling _to_ them. That creates a tension, that leads to 300-400 megabyte "driver downloads" filled with all kinds of crap.
300Mb for a graphics card driver?
You cannot be serious.
Not only that, it's pretty obvious that AMD Graphics are doing deals with the publishers of software and games to "tune" the performance of their applications.
How do I know this? My graphics card crashed again this morning, (not the whole machine, just the card dropped and re-installed) and because I hunt down the causes of these things, I noticed the system log entry
Process C:\Windows\System32\SET645.tmp (process ID:3660) reset policy scheme from [hex block]
Since I'm not fond of anonymous ".tmp" executables changing my system settings, I had a look at the files. (There were several) They contain strings like:
...so I'm guessing they're automatic updates downloaded by Catalyst. If you look carefully at some of the files, you notice lists of executable names for games and other programs. Some games I've never had installed on my system. Some apps (like DirectX and Chrome) we all have.
I'll include just a small sample of that list: (sorry about the UTF16 spaces)
5 C O D - B l a c k O p s B l a c k O p s . e x e B l a c k O p s M P . e x e S k y r i m T E S V . e x e S t a r C r a f t 2 S C 2 * . e x e 3 D M a r k N E X T 3 D M a r k I C F D e m o . e x e 3 D M a r k I C F W o r k l o a d . e x e 3 D M a r k . e x e 3 D M a r k C m d . e x e M a s s E f f e c t 3 M a s s E f f e c t 3 * . e x e W h i t e L i s t A p p U n i g i n e . e x e S a n c t u a r y . e x e L e o _ D 3 D 1 1 . e x e M e c h a _ D 3 D 1 1 . e x e L a d y b u g _ D 3 D 1 1 . e x e C o r e T e c h 2 _ X 6 4 _ 1 0 . e x e C o r e T e c h 2 _ X 6 4 _ 1 1 . e x e C o r e T e c h 2 _ X 8 6 _ 1 0 . e x e C o r e T e c h 2 _ X 8 6 _ 1 1 . e x e B a t m a n A C . e x e h n g . e x e R e n e g a d e O p s . e x e S a i n t s R o w T h e T h i r d _ D X 1 1 . e x e G a m e C l i e n t . e x e A n n o 4 . e x e f c 3 _ b l o o d d r a g o n _ d 3 d 1 1 . e x e f c 3 _ b l o o d d r a g o n _ p _ d 3 d 1 1 . e x e f c 3 _ b l o o d d r a g o n _ r _ d 3 d 1 1 . e x e f c 3 _ b l o o d d r a g o n _ r t _ d 3 d 1 1 . e x e N Z A . e x e a r m a 3 . e x e z a t . e x e M a d M a x . e x e 3 D M a r k S k y D i v e r 3 D M a r k S k y D i v e r . e x e T a l o s . e x e T a l o s _ U n r e s t r i c t e d . e x e T a l o _ D e m o . e x e M u r d e r e d S o u l S u s p e c t F a t e G a m e - W i n 6 4 - T e s t . e x e M u r d e r e d . e x e H i t m a n A b s o l u t i o n H M A . e x e F i f a O n l i n e 2 F F 2 C l i e n t . e x e D i a b l o I I I D i a b l o I I I . e x e D i r t S h o w d o w n s h o w d o w n . e x e s h o w d o w n _ a v x . e x e s h o w d o w n _ d e m o . e x e s h o w d o w n _ d e m o _ a v x . e x e K r a t e r K r a t e r . e x e M a x P a y n e 3 M a x P a y n e 3 . e x e T J 3 T J 3 . e x e
You'll note they have special detection of the 3DMark _benchmarks_. That's a worry by itself. How do you trust a video card driver that auto-detects benchmark software? (and presumably switches on specific settings just for that case)
What's more concerning - if getting an entry like this is how you gain 'top performance' for your software (because apparently the basic video card drivers aren't up to the job by themselves) then how exactly does your company gets its optimal settings into this list? Does monetary compensation change hands? How much? Can Indie developers afford it?
I'm sure there are nice excuses for this behavior, (like enabling new graphics modes for legacy games) but it also enables a whole class of dodgy practices for AMD and un-obvious behavior for the user. The AMD graphics drivers don't really do what you ask... they do it "better!", according to the latest update.
What's amusing is - if the auto-update system didn't keep crashing and properly cleaned up it's temp files, I might never have seen this list in such obvious plain-text.
So, I'm sick of this crap. For my next graphics cards, I'm going back to NVIDIA, to get me some of that sweet CUDA lovin' and stability. If that means changing the rest of my machine to Intel, well, so be it.
Here's tonight's screenshot from Astromech: A very early preview of the new "Hex" Editor.
It doesn't edit hexadecimal code -it edits dependency trees. I'm sure at first the whole thing looks a little hand-drawn, a bit too good, but in fact all of the connection lines are auto-routed by Dijkstra's algorithm on a hexagonal grid - which I find gives more pleasing results than square grids, assuming you can handle the math.
This is a "first preview" of what's going to be the cap-stone of Astromech before I finally push it out the door - the integrated script editor needed to tie together all the other parts.
I'm trying to do an end-run around all the problems of text, keyboards, languages and localization, and comp.sci jargon in general - by having another tilt at one of the big windmills of computer science - Visual Code Editing. Representing code graphically, rather than as text.
Many before have tried and failed. I'd probably be doomed to fail if I also tried to create a 'generic' programming language, but I have a very specific set of needs that isn't fully Turing complete - mostly I just need to connect up predefined modules into processing chains which have well-behaved startup and shutdown semantics.
These scripts will be hidden inside every Astromech item and level, responding to clicks and collisions and requests to add new 3D models into the visible scene. They're already there, but large chunks of JSON are a pain to edit. I need something better.
This is one of those "the future is here" moments. The first 'tv show' transmitted from VR.
The Foo Show - Firewatch Tower Tour Episode
It's clunky, their arms don't move properly because the inverse kinematics forgot to include shoulders, and in terms of content - it's a bunch of people wandering around a small room looking intensely at every-day objects like teenagers on their first acid trip.
But it's also groundbreaking. Will's completely right about how little it takes before you anthropomorphise their chunky avatars into "real people". Ten minutes in and I forgot they were polygons.
And at the end, they wave goodbye. Such a simple, utterly human gesture. The first time anyone has waved to me from VR.
FooVR.com is in early days still. The resolution will improve, structured motion systems will replace the polygons with photogrammetry, the inverse kinematics will get better, and the "virtual sets" will evolve and explore the limits of what's visually possible.
But they got first post. And that's what matters.
I've been expectantly waiting for this day for over 20 years, and pushing the technology and art behind it. This concept is as old as Gibson's "Neuromancer", or Simmon's "Hyperion". Now it's real. We finally get to explore not just the idea, but it's consequences.
Inventories! They've been in every RPG and MMO for the entire history of computer games. Type 'invent' into 'advent' if you don't believe me.
So, you'd think the finer points of "inventory management theory" would have been long hashed out by the games development community, and you'd be wrong.
Gamasutra has two articles; one in 2010 and then another in 2015. That's the opposite of a hot topic.
"Inventory Management Sucks!" is a short reminder on what the player probably expects out of their inventory system. Too short.
"Loot Quest: From Ruminations to Release" gets much more into the issue, from the point of view of the choices one makes building the inventory system, and how it affects the game mechanics. Those guys make explicit and careful choices, because "a streamlined inventory was seen as one of the highest priorities" for their "heroes-with-equipment premise".
Of course, you can't discuss inventory systems without referring to the grand-daddy of the genre, World of Warcraft. Although more as a cautionary tale, many would say.
Loot Porn.
Something that's taken for granted with all these 'Inventory' systems is that items are scarce. They are games, after all. Items in games are intended to be rewards, and often consumable. This can lead to entire 'virtual economies' for 'goods' that are really just one entry in a database table somewhere, linking a pre-defined 'item' object into your inventory space.
When you 'craft' an item in these MMOs, what you're doing is collecting a bunch of predefined database tokens which you exchange (via server calls) for another predefined database token. You're not making anything new. Even though it can sometimes feel 'unique' because stats are randomly rolled or cute names are chosen from a big list.
Remember how innovative it seemed when, in Diablo II, you got access to the ability to name one item? With your own name, but still. That mechanic alone resulted in entire generations of characters being created with names that looked good on a sword.
And yet, the amount of time and effort trading these game items has been incredible. Big companies like Blizzard have had to face the question of whether allowing characters to transfer items in-game will create an entire secondary 'trading markets' and whether they allow that. (Or, since you can't stop it, whether they banhammer the players they catch, or try to set up their own market and get a slice of that pie.)
As you might know, I'm writing a game-ish VR environment thingy called "Astromech". Think of it as a level designer. You place geometry, define what the sky looks like, etc.
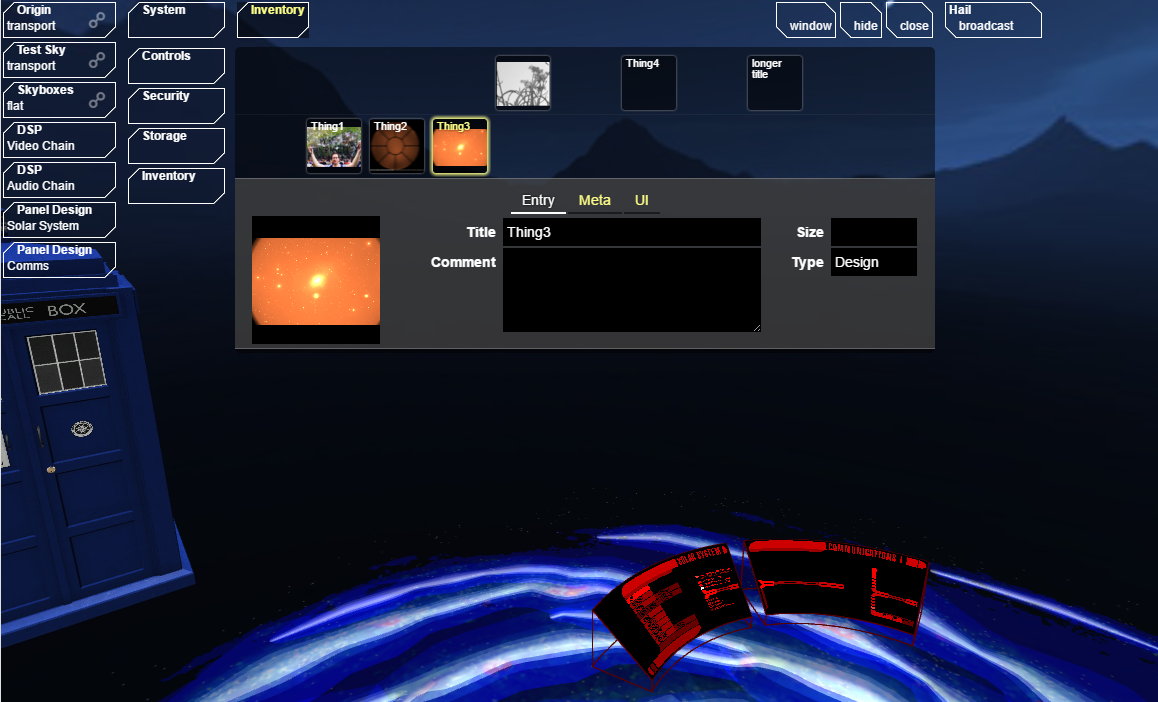
I found I was building an "Asset Manager" for all the content that goes into a level. And because Astromech is a 'world builder', I like the concept of just picking up 'items' in one level, putting them in your 'inventory', and then dropping them into others.
That means that, in astromech, Items don't come out of a predefined set. They start as directories of asset files, from which visible things in the level are instanced. They are 'program scripts'.
That makes "item crafting" in Astromech a whole new thing. For a start, items can be created by just dragging a filesystem directory into the inventory screen. The directory is rifled through for metadata and assets, and you get a new inventory item! Want a different item, then edit the files and go again! Want to change the icon or title or comment, then do!
The beginnings of Inventory Management in Astromech. Damn, where did I leave that dataset of all known asteroids in the solar system?
That's a concept most games go to extreme lengths to avoid. Because in a competitive system, you don't want other people arbitrarily increasing their power by modifying their tools. But in a co-operative system about building "virtual machines" to solve real-world problems, you actually want the other "players" to be all that they can be.
Because if they build some incredible item that detects bird-song in audio streams, or reconstructs 3D scenes from multiple photos, (using the DSP 'components' that Astromech provides) then that becomes something they can share. Something not originally programmed into the 'game' by me.
How? Just walk up to their avatar in VR and open their 'shop' of public items. All the tropes of inventory trading in MMOs are just the accountancy of database management dressed up in a pikachu suit.
This allows other niceties, such as users storing the items in their own local machines, and doing direct peer-to-peer sharing without central servers. "Duping items" is assumed. Some are just URLs.
There's a LOT of little details to work out, but the paradigm of item sharing in MMOs is far more friendly than file sharing systems like dropbox. I've prototyped the issues now, and I can see where it's all going.
Minecraft introduced "item transforming items" like furnaces and workbenches. I'm going a step further, to "item compilers" which effectively craft unique pieces of functional 'software' from source components. That's what an Astromech item is.
Astromech's real job is to create a space where all these "virtual devices" can play together in a shared 3D environment, and connect with each other, while protecting the user's browser from malicious code, and devices from each other. (Because, this is all in a web page!)
Remember, the secret is to bang the rocks together, guys.
Possibly the closest equivalent available today is in Steam's VR demo "The Lab".
Towards the end, after the Tested team has played most of the mini-games, the table in the hub room fills up with devices they've 'collected' from the various games. Balloon inflaters, bows and arrows... and they begin to delight in the way these tools can be played with and combined, just for their own sakes. And unlike most games, the tools aren't purely destructive.
So I procrastinated from other things and made a video showing off the new Skyshaders in Astromech, set to some of the music I listened to while developing it.
Instead of spending ages building geometry for your 3D worlds, why not just define a mathematical 'field' function that uses fractals and folded space and pseudo-random noise and all kinds of other tricks? It certainly saves on the disk space.
Think of it as a kind of disguised Mandelbrot set. You can generate infinite variation from a carefully iterated function, and often you can zoom all the way down and variation just keeps appearing.
The hard part is combining these 'shader' backgrounds with actual geometry. Until recently, this wasn't possible to do in the browser, but a new WebGL extension (EXT_frag_depth) allows you to control the 'fragment depth' of individual pixels, (ie: skyboxes can now push parts of themselves into the foreground.)
Fortunately, it's a trick I've managed to implement in Astromech.
So now, I can do this kind of thing: take a classic 3D model (saved to COLLADA format from blender) and compose it with a procedurally generated 'skybox' that I call a 'skyshader'.
I hope to do a video shortly, showing off these fully animated 3D environments.
I've had weeks messing around with the API, listening to the lectures, and reading the other blogs. First thing you notice... there's not a lot of detail, and not a lot of stories of people using it. I assume they're all quietly working hard.
And actually, there's a lot of blustery crap in blogs about how you can never possibly do real crypto in the browser. Because why? Um, because you can't trust the browser, that's why. I mean, sure, otherwise you have to trust the operating system, but that's completely different.
And besides, Javascript isn't a real language anyway, they'll grumble. Because nobody likes losing the language wars.
So first, the good. Here's what it looks like when you've got a modern (Chrome / Mozilla) browser and you can use all the HTML5 :
var crypto_subtle = window.crypto.subtle || window.crypto.webkitSubtle;
function create_identity(meta,algo) {
meta = meta || {
name: "anonymous",
created: (+new Date),
};
algo = algo || {
name: "ECDH",
namedCurve: "P-521", //can be "P-256", "P-384", or "P-521"
};
var ident = { algo:algo, meta:meta };
return crypto_subtle.generateKey(
algo,
true, //whether the key is extractable (i.e. can be used in exportKey)
["deriveKey", "deriveBits"] //can be any combination of "deriveKey" and "deriveBits"
)
.then( function (key) {
console.log(key);
return Promise.all([
crypto_subtle.exportKey(
"jwk", //can be "jwk" (public or private), "raw" (public only), "spki" (public only), or "pkcs8" (private only)
keys.privateKey //can be a publicKey or privateKey, as long as extractable was true
)
.then(function(keydata){
ident['private'] = keydata;
}),
crypto_subtle.exportKey(
"jwk", //can be "jwk" (public or private), "raw" (public only), "spki" (public only), or "pkcs8" (private only)
keys.publicKey //can be a publicKey or privateKey, as long as extractable was true
)
.then(function(keydata){
ident['public'] = keydata;
}),
]).then(function() {
return ident;
});
});
}
That code is complete, no library dependencies. You could cut-and-paste it into any script. What does it do? It generates an Elliptic Curve public/private keypair, serializes the keys, and returns the whole chunk of JSON-y goodness in a Promise.
It's the core operation to create a "cryptographic identity" for future operations like signatures or encryption or link security.
If you don't know about EC6 Promises that are now standard in all browsers, go read about that instead. Go, go! That's even more important!
So, what's the bad news? Well, Apple and Microsoft are being predictably slow in implementing the good and useful (the less kind would say the "not horribly broken and unsafe") algorithms that we badly need, such as the Elliptic Curve Diffie Hellman (ECDH, use above) or Elliptic Curve Digital Signature Algorithm (ECDSA) that are about 100 times faster, and yet 10 times more secure, than the previous generation of RSA-based algorithms.
You may have heard that everyone wants to deprecate SHA-1 as being utterly broken now. Guess which algorithm has near-universal support across all browsers?
There's a reason for this, and that reason is at the center of a large fight. The W3C crypto API does what the W3C usually does - it standardizes, but without mandating a standard. If that sounds odd, it's basically the process of writing down what everyone currently does (the "state of the art") and saying "It's ALL legal!".
I personally don't mind this approach. It recognizes the fact that you can't force the browser makers to do squat. No matter how many "thou shalls" you put in the spec, they won't if they don't want to. So they best you can do is get all the documentation out into the open.
After a couple of years, all the crap shakes itself off, and we get left with a minimal core of useful tools that actually achieve a purpose, and work in the real world. Then there's usually a V2 of the specification which normalizes that.
The browsers already have extensive crypto stacks, SSL layers, key vaults, etc. So the API makes it easy for the browsers to expose a lot of that existing machinery, even though most of it isn't that useful inside the sandbox. It's what they've got for now, and they get to show it off. That's why all the browsers offer SHA-1 despite it being horribly broken - 'cause it was already there.
With the Web Crypto API, that means 80% of the spec is dead and pointless on arrival, Old crap that should have been left to rot, but got dragged along because some company wanted the backwards compatibility with some obscure password system, and didn't want to spend time and money working on writing the good stuff.
The spec is almost unreadable, even for a W3C recommendation, and I've been doing this a while. hundreds of pages long, and it still excludes a lot of the important technical detail via references to IEEE documents.
But that's OK. This is Javascript. Just dance around the landmines, and you'll be fine.
The browser makers that don't come up to snuff fast enough, they'll just get a polyfill. Sure, their browsers still won't be 'secure', but they'll be able to talk to our browsers, which suddenly are. The weak links will get pressure applied until they crack.
To be honest. Microsoft Edge is looking pretty good here. For most of the new HTML5 features, I'm pretty impressed with The Edge, and I'm happy to put it close 3rd after tied Chrome and Mozilla, but clearly closing the gap. They don't have ECDH yet, but it smells like they're close... certain error messages have the feeling of "not implemented yet" rather than "Not a feature!", if you know what I mean. They're even talking about protecting CryptoKeys stored in indexedDB on Edge at the OS level, which is the sort of thing that shows real thoughtfulness.
Safari is becoming the great standards holdout, especially so on iOS. Which is a big shame, because most of these new technologies are especially useful on mobiles. The fact that you can generate a secure Elliptic Curve key in milliseconds, even on low-CPU mobiles, (rather than seconds for RSA) means they're more useful and save battery life. (And that's the last platform you want to polyfill math routines on.)
The lack of ECDH/DSA on iOS is probably the biggest thing holding back HTML5 apps from communicating securely with each other, as general practice. But Apple's walking a tightrope there... if HTML5 pages become too capable, (with offline storage and crypto and media systems) who will visit the App Store?
But I'm not worried. This standard is being implemented surprisingly quickly, and as I said, there's a core of about 20% of the API which does some wonderful, fantastic, critically important stuff that the web has been waiting for, for decades.
That's the reward for anyone willing to dive deep into the API. I'm sure over time, there'll be some handy jQuery functions that make it all easy. But remember, they named it "subtle" for a reason.
So full disclosure first - I'm not a US citizen, and I really, really like flying robots. (I've built four of them.) I'm also a big fan of logic and consistency, which used to be a popular band back in the day but not so much anymore.
In the US, the Federal Aviation Administration has announced it will require all "drone" operators to register with the agency. Their definition of "drone" includes any remote controlled flying device over .55lb. (250 grams) That means quads, multis, foam planes, helicopters, blimps, balloons, and possibly Dune Buggies if they have too much 'hang time after sweet jumps. (it's unclear)
Paper planes are still fine. Any uncontrolled thrown thing is fine. 50-foot Frisbees are allowed. Rockets are cool. If you put foam wings on your iPhone, you're in a grey area deeper than shadow.
I'm not in-principle against enhanced safety, but this doesn't do that. The word "Overreach" is being used a lot. Congress explicitly said they couldn't do this. This moves the FAA from regulating a few dozen major airlines, to regulating the behavior of millions of private US citizens.
Quick review of what the FAA is: It got it's major "powers" in the 1960s, at a time when passenger planes were colliding over New York and dropping flaming wreckage on sleeping people in their apartments. People didn't like that. So the response was to invent the Air Traffic Control system and give the FAA powers over civil aviation, instead of letting the Airlines make up their own rules.
This has done a great deal to improve air safety. But it should be noted that planes still crash on New York quite a lot. There were the famous 11th September 2001 incidents, but who remembers Flight 587? which two months later crashed onto Queens because Air Traffic Control had told them to take off into the backwash of another plane, and some "aggressive piloting" caused the tail stabilizer to snap off. At a time when you'd think they'd be paying attention.
In fact, if you look at the big accidents (rarely deliberate), they're all caused either by pilots crashing into things they couldn't see, (like mountains) or Air Traffic Control directing them to crash into things they didn't know were there (like other planes).
Not a single aviation fatality has actually occurred because of RC hobby planes. Which have also been flying since the 60's, long before modern brushless motors and batteries. (The 'gasser' era.)
Military drones have caused crashes, it's true... but not Hobbyists. In fact, there have been 400 major accidents caused by US military drones. (which are the size of a car, and often armed) They once hit a C-130 Hercules. (literally, the broad side of a barn) But the FAA doesn't regulate military air traffic. And it likes to exaggerate the civilian threat.
One of these things is not like the other.
So, the FAA has announced it will create a "Drone Registry", so that anyone who intends to do bad things with a drone will helpfully write their details on the device, and this will help police track them down and arrest them for bad behavior.
No, really! That's their cunning plan. Some cynical observers suggest this is just stage 1, and future stages will require anyone buying an RC device to provide registration at Point Of Sale, otherwise the whole concept is utterly useless. And then they'll have to regulate batteries, motors, and computers, because otherwise you just buy the parts off eBay and build it yourself.
Or alternately, if a Policeman sees you flying in a park, they can ask for your registration and thereby keep the sky safe from bad people.
So, all we have to do to eliminate the "drone threat" is to put millions of US citizens (many of them children) into a huge database that will be publicly accessible by anyone who wants their phone number and home address. The FAA will have enforcement powers over every family in the country.
One of my favorite things is the $5 registration fee. That doesn't sound like much, true, but that's also the same cost to register a full size Boeing 747 Jumbo Jet. Another sign that the FAA doesn't really distinguish between a hundred tonnes of flying metal and a piece of motorized foam-board.
This also costs $5 to register with the FAA.
It's a real one.
Amazingly, the US congress told the FAA they couldn't do this. The FAA went and did it anyway. Despite long-standing legislation that reads:
Notwithstanding any other provision of law relating to the incorporation of unmanned aircraft systems into Federal Aviation Administration plans and policies, including this subtitle, the Administrator of the Federal Aviation Administration may not promulgate any rule or regulation regarding a model aircraft, or an aircraft being developed as a model aircraft, if—
(1) the aircraft is flown strictly for hobby or recreational use;
(2) the aircraft is operated in accordance with a community-based set of safety guidelines and within the programming of a nationwide community-based organization;
Meanwhile the AMA (The Academy of Model Aeronautics, one of those "nationwide community-based organizations" the legislation mentions) has told all it's members to hold off on drone registration while they try to sort through all the conflicting reports. Latest news is that they intend to take legal action to fight the new rules.
And now, these people might get to weigh in.
Including the Notorious RBG!
So, in summary: the FAA wants every hobbyist over 13yo to put their details in a public database, (because, y'know, privacy of the general public is important...) contrary to existing law, and the leading community organisation wants to take it to court. Hobbyists are furious. None of the new rules will make the skies any safer.
It's a path that treats RC craft purely as a threat to "real airspace users", and ignores the immense opportunities. And it also puts the FAA on a collision course with civil liberties for the American public, and that's the kind of thing that gets them hauled before the Supreme Court which might strip them of their powers as unconstitutional overreach, (you can't even force Americans to register their guns!) and we'll have no oversight, which is even worse than bad oversight.
It's a shambles. A hypocritical, pointless, mess. Years will be lost fighting the "freedom vs order" civil war, instead of just pushing for technological solutions to what are essentially technological problems. (hint: GPS broadcast beacons & official listed "crashing zones" for RC craft that need to get out of the way of emergency crews. So models can automatically go "If I sense a medivac chopper nearby, I'll crash myself in the nearest zone".)
Instead, I'm sure everyone is busy stripping off their backups, flight loggers, and safety gear - to fit under the 0.55lb weight limit. Those parachute systems are heavy, y'know.
If you're like me, you've often thought, "I really need GPS on a high-resolution camera, and probably accelerometers too, so I can do photogrammetry."
OK, maybe you don't. Even my spellchecker doesn't like the word "photogrammetry", which is when you take a whole bunch of photos of something with the intention of creating a 3D model (or other measurement) from the imagery.
Like what land surveyors do when they fly over with cameras to create topological maps. And like that, it really helps to know exactly where you were, and how the camera was positioned. A lot of the new algorithms can get by without it, but there's a time cost, and a lot of pathologies can be avoided if we start with a good bundle estimate.
Here's what I did as a first go:
An Aerial Photograph of my Aerial Photography Machine
That's a Raspberry Pi model A, with the 2k camera and WiFi modules, connected to a UBlox Neo6 GPS I got from Hobbyking last year. Less than $90 of stuff, most of which has been used in other projects. (And will again)
Techno-periscopes Up!
So here's what you need to know first: It doesn't work.
Well, I mean all the independent bits work fine, but not all together. That's the point. To spoil the ending: When the camera is operating, so much multi-megahertz digital interference is generated by the flat cable connecting the camera module, that the GPS loses signal lock.
Thar's yer problem right thar, boyo! The big flat white thing what's right near the little square doodad. And all bendy, too!
I'm sure I could also make a gripping yarn about how I bravely tracked down and cornered the bug, and how developing many features at once (streamed low-latency WiFi video, plus GPS) is a great way to find the problems, but leave yourself very confused about what causes them.
Close-up of the connections, showing how easy it is to wire a 3.3v GPS to the Pi. Standard linux 'gpsd' is used to decode the signals. The plastic cap of the left is just to protect that end of the connector from physical damage/shorts.
For a long time I assumed it was the WiFi streaming part, since it's an RF transmitter, and the GPS is an RF receiver, and all of it is cheap as beans, so logically... but no! Those parts are well engineered and stay out of each others bandwidth. You can WiFi and GPS just great. But the moment you start recording video to /dev/null, the GPS lights go out. That was the clincher.
If you're taking still photos, it's mostly fine. The GPS can stay locked on, and the brief static bursts during the camera shots are ignorable.
But I wanted video. And the moment you open up the throttle, it all fails.
Now, the obvious potential solution is to wrap a foil shield around the flat ribbon cable, especially where it bends, but that's something I'll need to do with great care, otherwise I've potentially got bits of foil flapping against the main electronic components and that's when the magic smoke comes out. There's also the question of how much of the digital path is exposed on the board. That would be harder to fix.
Perhaps a ground plane to shield them from each other; but shoving sheets of tin or copper in between is going to cause other issues, like making the WiFi directional, and other near-field effects. Argh.
So, you're saying the correct solution is a tiny Tinfoil Hat for the electron gnomes? Riiigghhtt...
Also, while the GPS and cable are pretty much right next to each other for illustrative purposes, I can assure you I tried moving the modules as far as I could (cable allowing) and it didn't help. I'm sure I could manage it with a long enough GPS extension cord, but if it can't fit in the one box, It's not very convenient.
But it you have a choice, plan on spreading the pieces out. That's probably your best bet.
So, alas, I don't have any guaranteed solutions to the problem yet. But I wanted to warn 'ye anyways.